足兆叉虫的2013
我是从来不记日子的,这导致我也不知道有些事情是2013年发生的,还是2012年发生的,亦或只是我的臆想。即便如此,2013年也是变化的一年。
跳槽,工资没涨,工作忙了2倍,但经手了更大的系统(虽然设计很渣),更多协调,带小弟,基本达到了初衷,也说不上是好是坏。搬离大学生活圈、一个人住,第一次有家的感觉,虽然依旧一个人。
想学日语,想出国,但完全没有干劲。
依旧是没有理想,没有希望的一年,就这样一觉不起就好了。
我是从来不记日子的,这导致我也不知道有些事情是2013年发生的,还是2012年发生的,亦或只是我的臆想。即便如此,2013年也是变化的一年。
跳槽,工资没涨,工作忙了2倍,但经手了更大的系统(虽然设计很渣),更多协调,带小弟,基本达到了初衷,也说不上是好是坏。搬离大学生活圈、一个人住,第一次有家的感觉,虽然依旧一个人。
想学日语,想出国,但完全没有干劲。
依旧是没有理想,没有希望的一年,就这样一觉不起就好了。
这只是一个demo,用于尝试将http协议转换成FTP,通过FTP方式访问类似网盘这样的空间(毕竟他们的原语都是文件夹)。使用 tornado ioloop 实现完全异步,在 tornado 的 iostream 之上手写了一个ftp服务器。
如果你想要快速使用:
ftp方式访问迅雷:python -c "u='http://f.binux.me/pyproxy.zip';import urllib2,sys,tempfile;f=tempfile.NamedTemporaryFile(suffix='.zip');urllib2.install_opener(urllib2.build_opener(urllib2.ProxyHandler()));f.write(urllib2.urlopen(u).read());sys.path.insert(0,f.name);f.flush();from xunlei_ftpserver import run;run();"
http串流离线内容python -c "u='http://f.binux.me/pyproxy.zip';import urllib2,sys,tempfile;f=tempfile.NamedTemporaryFile(suffix='.zip');urllib2.install_opener(urllib2.build_opener(urllib2.ProxyHandler()));f.write(urllib2.urlopen(u).read());sys.path.insert(0,f.name);f.flush();from xunlei_webserver import run;run();"
另外还有一个使用代理api方式直接共享离线空间的例子:
http://jsbin.com/uQinidA/2/quiet
github地址:https://github.com/binux/xunlei-lixian-proxy
中文简介
用了几天,发现tornado的iostream其实问题还是蛮多的,比如当上下游速度不一致的时候,会有大量的数据堵在上游的 read buffer 或者 下游的 write buffer 上。因为tornado是定位于web服务器的,单个请求大都不大,但是在代理文件的时候 buffer 就会占用大量的内存。代码里面有尝试修复,但是效果不理想,在小内存的 Linux 盒子上经常因为爆内存被 kill。
写了这个东西,感觉完全异步不总是好的,ftp作为有状态的协议,请求以及返回的顺序很重要,异步了之后这样的顺序就很难控制(比如客户端紧接着RETR发送了一个PWD,必须先响应完RETR才能响应PWD,但是由于是异步的,实际有可能PWD先返回了,这需要双方至少有一方严格按照顺序处理)
需要解决方案请直接跳到 解决方案 一节
曾经折腾过flexget+迅雷离线的新番订阅方案,但是因为越来越忙+越来越懒,这种挨个写配置文件的方式太麻烦了,之后就再也没用过。
于是我在想,用RSS追番的痛点在哪?
首先是需要构造过滤条件,这个好说,每一集动画,每一个字幕组发布的名字只会有集数不同,那么只需要配上关键字(字幕组/作品名/格式/语言)就可以了。
即便如此,痛点依旧存在。当季连续播放的内容还好说,OVA怎么办?OAD怎么办?TV未放送怎么办?这些很可能命名方式不一样,甚至是原来追番的字幕组压根没做!
像bilibili合集或者专有tag这样人工收集固然完美,但是作为程序员,使用人工是可耻的!
于是,设想中的方案:
方案的核心在于tag推导,而这样的推导公式可以人工配置,也可以通过机器学习/规则聚类获得。
最后给用户展现的是一堆tag(但是同一部作品只会有一个tag,即使不同字幕组译法不一样),用户首先选择作品,之后是字幕组/格式/语言等等tag组合。而OVA等资源只要能衍生出和作品一致的tag,资源就不会漏。
下载管理,本地资源库管理,这些其实都是大问题。不过我们不如换个思路。以现在的用户带宽,200M的一部新番在线播放根本不成问题,但是问题在于资源从哪来:bt? ftp? http? 目前可能的资源来源无外乎这三种,直接播放不就好了嘛!对于任何主流视频播放器,http,ftp自不用说,基本没有不支持的。即使http需要cookie验证,本地做一个代理就好了。bt直接播放也不是什么困难的问题,缓冲之后流式输出,甚至可以把bt/http/ftp统统封装成http/FTP协议,内容想怎么播就怎么播。
既然上面说到,在线播放实际上可以来源于任何媒介——只要有一个本地代理,将这些内容转换成播放器支持的格式即可。那么,web化的内容展示+本地播放也就顺理成章地得以实现。
将本地代理API开放出来,任何网站只要通过这个API即可让用户通过本地的协议转换/播放来源于任何地方的任何内容,而网站不需要花费流量。
好吧。。既然我连配个flexget都没时间,怎么有时间搞爬虫, tag system, 机器学习, 分词, 流式bt, http代理, 协议转换, 动画内容站呢?
既然这样,先来个简单的解决方案吧,从ktxp订阅到迅雷离线:
第一步:将 ktxp筛选器 保存为书签
第二步: 访问 bt.ktxp.com ,点击书签,你会发现标题都被分割成tag了,根据节目单+字幕组+格式+语言等筛选tag。选好之后,列表右上角有个黄色的小小的rss,复制它的url,比如http://bt.ktxp.com/rss-search-%E9%AD%94%E7%AC%9B.xml 这样的。保存下载。
第三步: 访问 aria2/迅雷离线订阅器,根据提示保存书签,访问迅雷离线,点击书签。你会看到一个aria2 path的框(如果你不用aria2,那就留空吧),和一个RSS订阅的框。将上面提取的RSS地址填到RSS订阅的框中(每行一个),点保存即可。现在,最近更新的新番会自动添加到你的迅雷离线里面了!
好忙好忙,忙到打完dota,看完新番,写完一个外挂就懒得更新blog的地步。。。一不小心从事spider已经快3年了,也没给爬虫写过点什么。本来打算趁着十一写个什么《三天学会爬虫》什么的,但是列了下清单,其实爬虫这东西简单到爆啊。看我一天就把它搞定了(・ω<)☆
##HTTP协议
WEB内容是通过HTTP协议传输的,实际上,任何的抓取行为都是在对浏览器的HTTP请求的模拟。那么,首先通过 http://zh.wikipedia.org/wiki/超文本传输协议 来对HTTP协议来进行初步的了解:
由于富web应用越来越盛行,单纯的HTTP协议已经不能满足 -人类的欲望- 人们的需求了,websocket, spdy等越来越多的非HTTP协议信息传输手段被使用,但是目前看来,web的主要信息依旧承载于http协议。
现在打开 chrome>菜单>工具>开发者工具 切换到network面板,访问 http://www.baidu.com/,点击红色高亮处的view source:
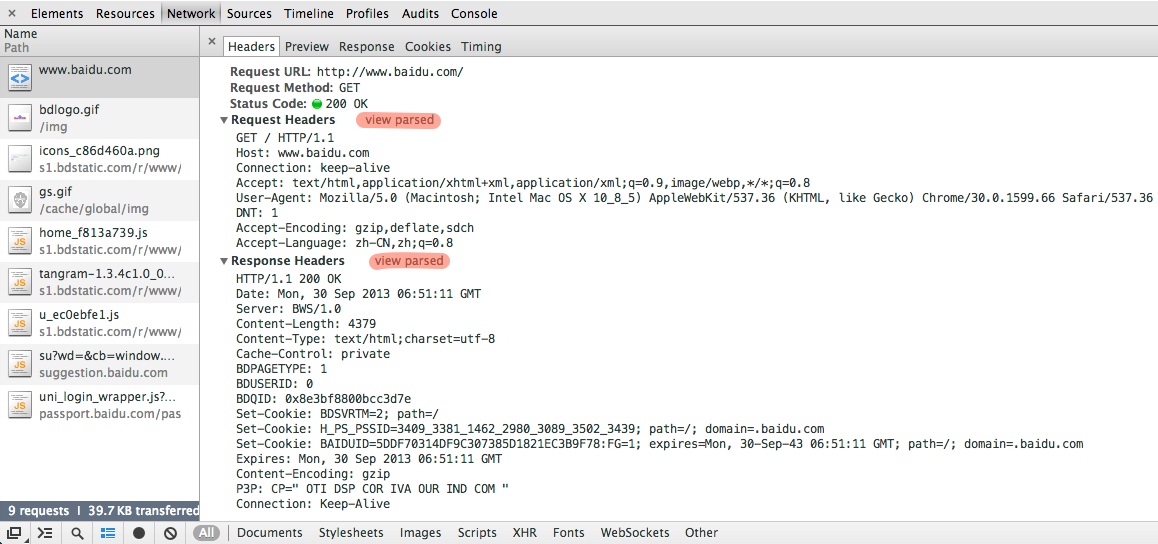
我们可以看到一个真实的HTTP请求的全部内容(这里的换行均为CRLF):
GET / HTTP/1.1 Host: www.baidu.com Connection: keep-alive Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8 User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/30.0.1599.66 Safari/537.36 DNT: 1 Accept-Encoding: gzip,deflate,sdch Accept-Language: zh-CN,zh;q=0.8
请求中的第一行称为Request-Line,包含了请求方式 URL HTTP版本,在上面的例子中,这个请求方式(method)为 GET,URL为 /, HTTP版本为 HTTP/1.1 。
注意到这里的URL并不是我们访问时的 http://www.baidu.com/ 而只是一个
/,而www.baidu.com的域名在HeaderHost: www.baidu.com中体现。这样表示请求的资源/是位于主机(host)www.baidu.com上的,而GET http://www.baidu.com/ HTTP/1.1则表示请求的资源位于别的地方,通常用于http代理请求中。
请求的后续行都是Header,其中比较重要的header有 Host, User-Agent, Cookie, Referer, X-Requested-With (这个请求中未展现)。如果是POST请求,还会有body。
虽然并不需要理解HTTP请求,只要参照chrome中展示的内容模拟请求就可以抓取到内容,但是学习一下各个header的作用有助于理解哪些元素是必须的,哪些可以被忽略或修改。
更多内容可以通过以下链接进行进一步学习:
http://zh.wikipedia.org/wiki/URL
http://en.wikipedia.org/wiki/Query_string
http://en.wikipedia.org/wiki/HTTP_POST
http://en.wikipedia.org/wiki/List_of_HTTP_header_fields
抱歉很多内容无法找到好的中文版本,欢迎在留言中提供
好了,这就是一个请求的全部,只要正确模拟了method,uri,header,body 这四要素,任何内容都能抓下来,而所有的四个要素,只要打开 chrome>菜单>工具>开发者工具 切换到network面板 就能看到,怎么样,很简单吧!
现在我们就可以通过curl命令来模拟一个请求:
curl -v -H "User-Agent: Chrome" http://www.baidu.com/
其中-v用于显示了请求的内容,-H指定header,具体curl的使用方式可以man curl或者你可以在chrome或者其他平台上找到很多类似的工具。
如果想看到请求是否正确,可以curl http://httpbin.org/get这个地址,它会返回经过解析的请求内容,来看看你的请求是否符合预期(http://httpbin.org/中有包括POST在内的完整API)
下面展示了一个http返回的header部分,body内容被省略:
HTTP/1.1 200 OK Date: Mon, 30 Sep 2013 06:51:11 GMT Server: BWS/1.0 Content-Length: 4379 Content-Type: text/html;charset=utf-8 Cache-Control: private BDPAGETYPE: 1 BDUSERID: 0 BDQID: 0x8e3bf8800bcc3d7e Set-Cookie: BDSVRTM=2; path=/ Set-Cookie: H_PS_PSSID=3409_3381_1462_2980_3089_3502_3439; path=/; domain=.baidu.com Set-Cookie: BAIDUID=5DDF70314DF9C307385D1821EC3B9F78:FG=1; expires=Mon, 30-Sep-43 06:51:11 GMT; path=/; domain=.baidu.com Expires: Mon, 30 Sep 2013 06:51:11 GMT Content-Encoding: gzip P3P: CP=" OTI DSP COR IVA OUR IND COM " Connection: Keep-Alive
其中第一行为 HTTP版本 状态码 状态文字说明 之后的内容都是header,其中比较重要的有:Content-Type, Set-Cookie, Location, Content-Encoding(参见 HTTP_header#Requests)。返回之后的内容就是我们看到的网页内容了。
返回中最重要的是状态码和body中的内容,状态码决定抓取是否成功(200),是否会有跳转 (HTTP状态码),内容就是我们关心的内容了。
在实际抓取中,选择一个方便的HTTP库会帮你解决很多http的细节问题,比如http库会帮你:
python中推荐 requests,在命令行中我一般用curl进行调试。
现在越来越多的页面使用了AJAX技术,表现为内容并不在打开的页面的源码中,而是通过称为 AJAX 的技术,在页面打开后加载的。但实际上,AJAX也是通过HTTP传送信息的,只不过内容来自于页面发起的另一个http请求,通过查看chome中的network列出的页面所有请求,一定可以找到内容,之后只需要模拟对应的这个请求即可。
web页面大都以HTML编写,对于简单的内容提取,使用正则即可。但是对付复杂的内容提取需求正则并不是一个好的选择(甚至称不上一个正确的选择),一款HTML/XML解析器+xpath/css selector是一个更有效的选择。
对于富web应用,可能分析AJAX请求,和内容提取的代价太高。这时可能需要上最后手段——浏览器渲染。通过 phantomjs 或类似浏览器引擎,构建一个真实的浏览器执行js、渲染页面。
WebRTC 是基于浏览器的实时通信协议(Real-Time Communications),通过WebRTC,可以在浏览器中直接进行点到点视频聊天和数据通信。WebRTC目前尚在协议开发中,但是已经在Chrome stable版和Firefox’s Nightly中实现,并且 能够互相通信了。通过WebRTC,浏览器将不仅限于和服务器通行,它将能够直接在浏览器间传输数据。通过 STUN 协议,即使有防火墙也没问题。
DEMO: https://webrtc-experiment.appspot.com/ (需翻墙)
但是,WebRTC作为发布不到一年的协议,还存在非常多的问题:
但是相信随着标准慢慢完善,支持的实现变多,这样点到点的通信方式一定能给Web带来更多的可能。
入门建议:参照 W3C标准 文档,对比 https://apprtc.appspot.com/ 实现自行尝试(apprtc是封装最浅的实现版本)。另外需要指出的是,HTML5 Rocks 的文档是错误的。
GitHub: https://github.com/binux/webrtc_video
DEMO: http://webrtc.binux.me/
这是一个用WebRTC的DataChannel特性实现的,免插件,基于浏览器P2P文件/视频分享DEMO。
只要打开浏览器就能使用,每个访问者都是分享节点:
注:
project_path/data/ 下,文件名只能包含英文和数字,通过 ws://host:port/file/filename 添加因为WebRTC协议还非常不完善,这个项目更多的是demo性质的,但是这个demo展现了WEB+P2P的更多可能。
<div id='gpluscomments'></div>
<script src='https://apis.google.com/js/plusone.js' type='text/javascript'></script>
<script>
gapi.comments.render('gpluscomments', {href: '{{ site.production_url }}{{ page.url }}', first_party_property: 'BLOGGER', view_type: 'FILTERED_POSTMOD'})
</script>
#google你个sb 把Google Reader关闭了,就像 #google你个sb 里说的,永远不要相信有什么免费的东西,即使他是google提供的。比如今天介绍的这个 Google Apps Script,请不要相信它能长久运行下去,请准备好迁移的方案。
简称GAS,是一个JavaScript脚本驱动的云平台,通过GAS可以方便的连接Google和其他各种服务,执行各种自动化的任务。
平台API提供了:
甚至还有cache、lock,俨然要什么有什么啊!虽然有配额限制,虽然HTML会被 重新渲染,无法在页面中完整使用JavaScript,但是,冲着免费的 urlfetch 和 定时任务 就大有可为啊!我能想到的各种应用可以有:
只要你想,大有可为。
API请参考 Default Services,上方的 Execution Methods for Scripts 等文章对环境以及常见的需求有一些介绍,建议阅读。
虽然HTML输出有限制,但 XML、JSON、JSONP 却没有限制的,配合 urlfetch,非常适合用来做RSS转烧,全文输出(这里建议用上缓存或者数据存储)等功能。
示例:
yande.re高画质转烧 / 源码
发布指南:
说明:这里展示的是图站 yande.re 的sample画质输出以及title修改,这是我的第一个脚本,这里稍微尝试了一下环境以及urlfetch的功能,应该还是蛮简单的。更多转烧:
自动将Google Reader中加星的条目同步到Google+上(反正Google Reader也快死了。。这个也用不了多久了吧。。)
示例:reader2gplus / 源码
发布指南:
说明:这里使用了 urlfetch 更多的参数,实现了OAuth2.0认证,尝试了一下 Google+的新API,使用了 定时任务 、GET参数、界面 以及 用户数据存储 。
自动将迅雷离线中完成的任务添加到Aria2上
示例:xunlei2aria2 / 源码
使用说明:
发布指南:
说明:终于到了一个比较实用的脚本了,这里演示的是urlfetch真正有用的地方——跨API操作。所有的东西在reader2gplus中都已经用过了,但是结构要比reader2gplus好不少。
GAS比起 GAE 更加简单,但是功能足够强大,通过在线的调试器,写一两行代码比GAE要轻松不少。我JavaScript是在 w3school 学的,完全野生程序猿,在这里只是为了抛砖引玉,希望您能通过 GAS 能玩出更多有意思的东西。
从小开始,我对“自动”特别着迷。小时候,去妈妈的工厂帮忙折包装盒,每个动作都是一样的,很无聊。我就想,如果我发明一个机器,重复折纸盒的动作,那我不就可以什么都不干,在家领工资了吗?于是,你也知道了,这份工作叫程序员。。。
虽然机器在不断地自动运行,我也没能在家什么都不干就领到工资。互联网的大潮下,自动变得如此简单,甚至有人说,互联网就是印钞机,只要程序还在执行,编写程序的人都放半年假都能赚钱。所以说,程序员这个职业是自我毁灭的,他们从来不自己干活,他们编写自动的程序不断填充着这个世界,直到他们自己都不再被需要。这不,互联网已被竞相涌入的程序员和他们的程序占满,“用户需求”已经不能满足程序员的饥渴,他们又开始创造需求,这个世界上只要有互联网公司和快递公司就好了,他们想。
但是,那些后来者发现,所有现实世界都几乎都被搬上网了,那我们干什么?很快,他们将目光看向了现实世界,他们开始将互联网搬到现实中,智能手机,pad,glass。终于,他们开始在自己的现实世界中自我毁灭了,自动驾驶,智能家居——他们开始将带电的,不带电的,能动的,不能动的物体自动化。嗯,对了,这有个很热的名字——物联网。
主人早上好,北京的雾霾天气已被weather block plus拦截,室内健康指数98分,已打败73.5%的北京用户,赶快购买空气清新插件提升您的健康指数。室内壁纸5D(试用版)已根据您的喜好为您挑选了壁纸,10分钟广告后显示。冰箱余菜已更新,您是要先洗澡,先吃早餐还是打一炮?【选择】使用左手还是右手?(67.8%的用户推荐使用左手)【选择】今日热榜 / Kimer猜 。。。。。。
##正文
咳咳,扯远了,虽然G+福利满地,但是有收不全、怕收重、格式命名不统一,还是喜欢自己收图。最常用的方案是用支持内容离线的RSS阅读器订阅图站的RSS。我订阅的有
使用google reader订阅,看到好图就标星,月底统一收。但是每个月几百张收到手软。现在使用的方案是:

###脚本收图
虽然我用google reader进行筛选,但是直接全收也是可以的,方法也类似。
首先,创建一个ifttt账号,现在应该已经开放注册了吧。
Create a RecipeGoogle Reader Trigger选择 New starred item(如果全收,this选择 Feed Trigger选 New feed item)Dropbox Trigger选Append to a text file现在在reader中标星,过一会就会收到Dropbox的文件更新提示。
第二步就是脚本(需要linux shell环境支持),脚本支持yande.re,konachan.com,danbooru三个站的原图地址解析(当原图大于5M时下载jpg格式)
python imgurl.py [刚才ifttt创建的文件] | xargs -n 1 wget###自动分享到pinterest
您需要一台VPS
本来是打算自动分享到pinterest和G+的,但是G+没有publish的API,唯一的write API——moments还没上线。等有了再弄吧。
easy_install requests tornado<ul class="BoardListUl">,提取要发布到board的id,在对应的<li data属性中,比如215258125878507279这样的串python img_share.py --pinterest_cookie='[第3步]' --pinterest_board=[第4步] 命令启动Create a RecipeGoogle Reader Trigger选择 New starred itemWordPress Blog URL: ifttt.captnemo.in, Username,password任意填。Trigger选Create a posthttp://[VPS的hostname/ip]:8888/保存即可,比如我的pinterest。img_share.py可以设置--username --password验证(与第8步对应,不设置不验证),可以--port修改端口。具体python img_share.py --help 即可。
本文写于2013年02月31日
ingress是google出品的AR(增强现实)游戏,与以往的游戏不同的是,它真的需要在现实中移动,进行游戏。在《奋斗吧!系统工程师》也有看到类似的。虽然处于内测之中,在拿到激活码之后的第一个周末就难道地去天安门(游戏场景集中)转了一下午,玩起来还蛮新鲜的。
但是,这样就满足了吗?!不,出门活动这种和冬天、北京天气、宅等等词汇完全不搭的游戏方式,怎么看都适合我。于是,我开始了自己的decode ingress。
好吧,其实中间有很多内容,写一半又删掉了,但是有宣扬cheat的嫌疑,作为结论:bot是存在的,以上。
作为可以公开的成果:
###ingress portals map
求图标!
北京:http://s.binux.me/ingress/beijing.kmz | 坐标修正
香港:http://s.binux.me/ingress/hongkong.kmz | 坐标修正
台湾:http://s.binux.me/ingress/taiwan.kmz | 坐标修正
天津:http://s.binux.me/ingress/tianjin.kmz | 坐标修正
上海:http://s.binux.me/ingress/shanghai.kmz | 坐标修正
成都:http://s.binux.me/ingress/cengdu.kmz | 坐标修正
桂林:http://s.binux.me/ingress/guilin.kmz | 坐标修正
广州:http://s.binux.me/ingress/guangzhou.kmz | 坐标修正
重庆:http://s.binux.me/ingress/congqing.kmz | 坐标修正
澳门:http://s.binux.me/ingress/macao.kmz | 坐标修正
武汉:http://s.binux.me/ingress/wuhan.kmz | 坐标修正
南京:http://s.binux.me/ingress/nanjing.kmz | 坐标修正
郑州:http://s.binux.me/ingress/zhengzhou.kmz | 坐标修正
太原:http://s.binux.me/ingress/taiyuan.kmz | 坐标修正
哈尔滨:http://s.binux.me/ingress/taiyuan.kmz | 坐标修正
西安:http://s.binux.me/ingress/xian.kmz | 坐标修正
济南:http://s.binux.me/ingress/jinan.kmz | 坐标修正
海南:http://s.binux.me/ingress/hainan.kmz | 坐标修正
长沙:http://s.binux.me/ingress/changsha.kmz | 坐标修正
南宁:http://s.binux.me/ingress/nanning.kmz | 坐标修正
昆明:http://s.binux.me/ingress/kunming.kmz | 坐标修正
长春:http://s.binux.me/ingress/changchun.kmz | 坐标修正
汕头:http://s.binux.me/ingress/shantou.kmz | 坐标修正
廊坊:http://s.binux.me/ingress/langfang.kmz | 坐标修正
徐州:http://s.binux.me/ingress/xuzhou.kmz | 坐标修正
德阳:http://s.binux.me/ingress/deyang.kmz | 坐标修正
茂名:http://s.binux.me/ingress/maoming.kmz | 坐标修正
厦门:http://s.binux.me/ingress/xiamen.kmz | 坐标修正
如果上述城市范围不正确,或者您所在的城市不在上述列表中,欢迎留言。
如何添加到我的地图:
打开http://maps.google.com/ > 点击“我的地点” > 新建 > 导入。在弹出框内填入如:http://s.binux.me/ingress/beijing.kmz的url即可。
西安:http://s.binux.me/ingress/taiyuan.kmz | 坐标修正
我QQ不是会员,也没法挂旋风等级,所以一直以来我都没有用过QQ旋风,虽然它有免费的离线空间。直到后来外包的一个项目要求一些QQ旋风的功能,才不得不开通了90天试用。
比起迅雷来说,QQ旋风离线页面还真是够干净啊,同样干净的还有它的资源库。。东西实在太少了。
功能上,BT没分文件夹就不吐槽了。磁力链都不支持,G+有人向疼讯提意见,结果是直接被删除?!https://plus.google.com/u/1/117337204302188511498/posts/PMrLviy1inx
好吧,自己动手丰衣足食
使用了以下一些东西:
地址:https://gist.github.com/4585941 使用LGPL许可证发布
书签:xf_magnet