pyspider 爬虫教程(二):AJAX 和 HTTP
在上一篇教程中,我们使用 self.crawl API 抓取豆瓣电影的 HTML 内容,并使用 CSS 选择器解析了一些内容。不过,现在的网站通过使用 AJAX 等技术,在你与服务器交互的同时,不用重新加载整个页面。但是,这些交互手段,让抓取变得稍微难了一些:你会发现,这些网页在抓回来后,和浏览器中的并不相同。你需要的信息并不在返回 HTML 代码中。
在这一篇教程中,我们会讨论这些技术 和 抓取他们的方法。(英文版:AJAX-and-more-HTTP)
AJAX
AJAX 是 Asynchronous JavaScript and XML(异步的 JavaScript 和 XML)的缩写。AJAX 通过使用原有的 web 标准组件,实现了在不重新加载整个页面的情况下,与服务器进行数据交互。例如在新浪微博中,你可以展开一条微博的评论,而不需要重新加载,或者打开一个新的页面。但是这些内容并不是一开始就在页面中的(这样页面就太大了),而是在你点击的时候被加载进来的。这就导致了你抓取这个页面的时候,并不能获得这些评论信息(因为你没有『展开』)。
AJAX 的一种常见用法是使用 AJAX 加载 JSON 数据,然后在浏览器端渲染。如果能直接抓取到 JSON 数据,会比 HTML 更容易解析。
当一个网站使用了 AJAX 的时候,除了用 pyspider 抓取到的页面和浏览器看到的不同以外。你在浏览器中打开这样的页面,或者点击『展开』的时候,常常会看到『加载中』或者类似的图标/动画。例如,当你尝试抓取:http://movie.douban.com/explore
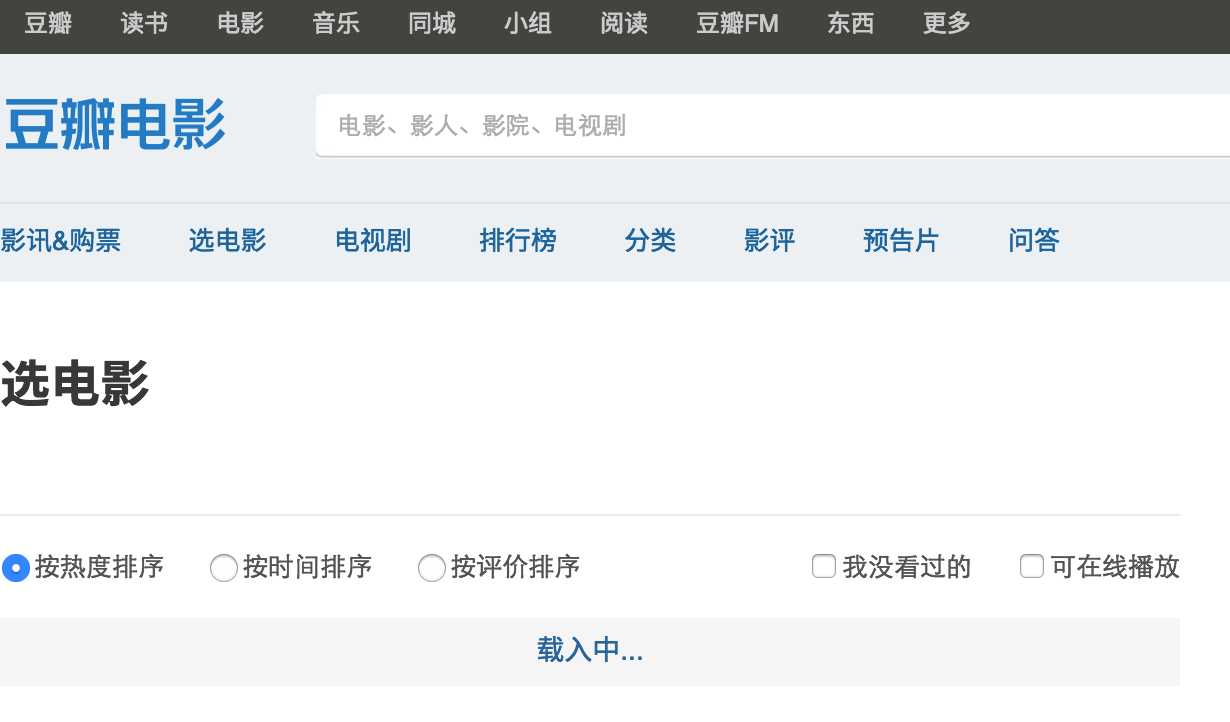
你会发现电影是『载入中…』
找到真实的请求
由于 AJAX 实际上也是通过 HTTP 传输数据的,所以我们可以通过 Chrome Developer Tools 找到真实的请求,直接发起真实请求的抓取就可以获得数据了。
- 打开一个新窗口
- 按
Ctrl+Shift+I(在 Mac 上请按Cmd+Opt+I) 打开开发者工具。 - 切换到网络( Netwotk 面板)
- 在窗口中打开 http://movie.douban.com/explore
在页面加载的过程中,你会在面板中看到所有的资源请求。
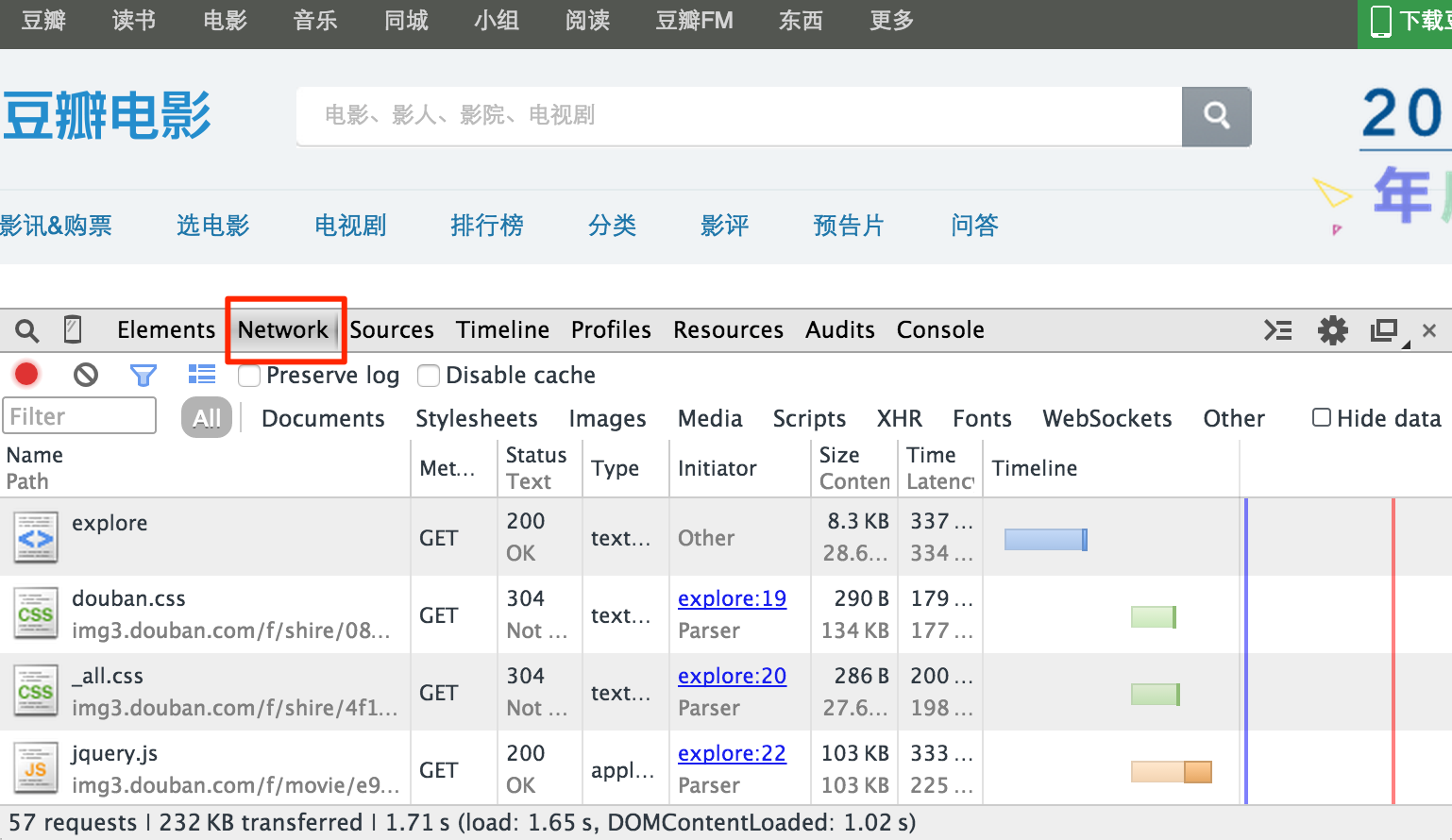
AJAX 一般是通过 XMLHttpRequest 对象接口发送请求的,XMLHttpRequest 一般被缩写为 XHR。点击网络面板上漏斗形的过滤按钮,过滤出 XHR 请求。挨个查看每个请求,通过访问路径和预览,找到包含信息的请求:http://movie.douban.com/j/search_subjects?type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start=0
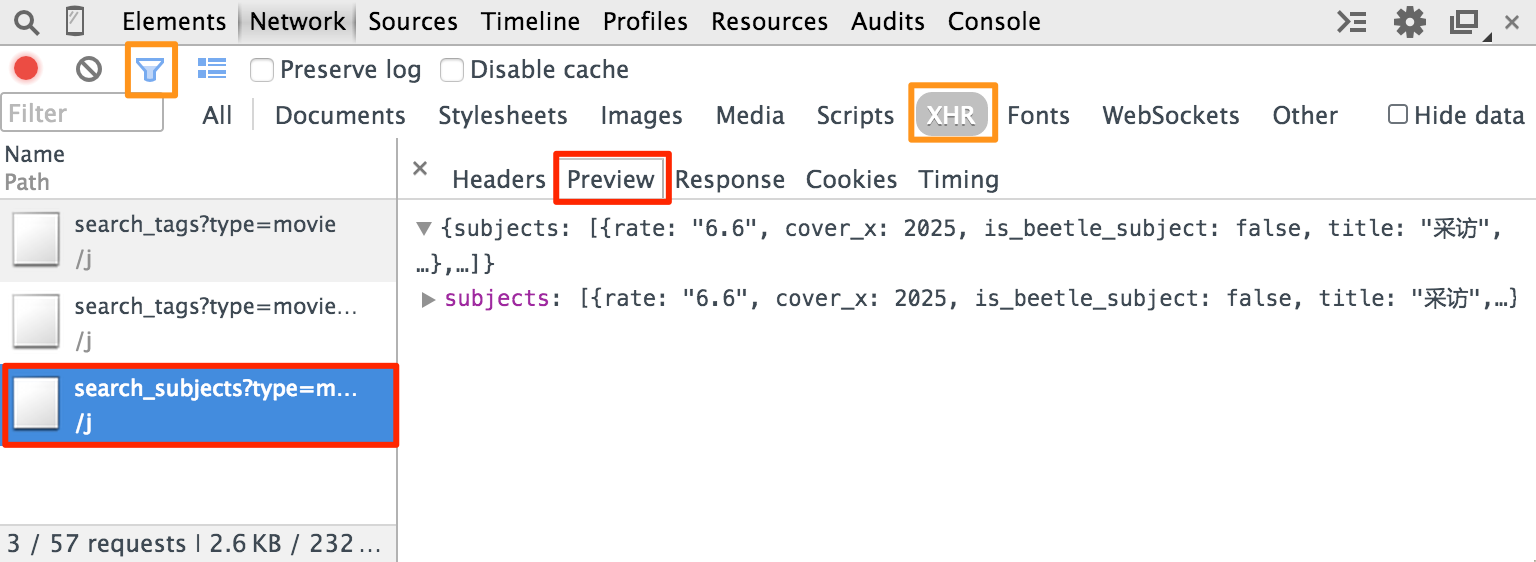
在豆瓣这个例子中,XHR 请求并不多,可以挨个查看来确认。但在 XHR 请求较多的时候,可能需要结合触发动作的时间,请求的路径等信息帮助在大量的请求中找到包含信息的关键请求。这需要抓取或者前端的相关经验。所以,有一个我一直在提的观点,学习抓取的最好方法是:学会写网站。
现在可以在新窗口中打开 http://movie.douban.com/j/search_subjects?type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start=0,你会看到包含电影数据的 JSON 原始数据。推荐安装 JSONView(Firfox版)插件,这样可以看到更好看的 JSON 格式,展开折叠列等功能。然后,我们根据 JSON 数据,编写一个提取电影名和评分的脚本:
1 | class Handler(BaseHandler): |
- 你可以使用
response.json将结果转为一个 python 的dict对象
你可以在 http://demo.pyspider.org/debug/tutorial_douban_explore 获得完整的代码,并进行调试。脚本中还有一个使用 PhantomJS 渲染的提取版本,将会在下一篇教程中介绍。
HTTP
HTTP 是用来传输网页内容的协议。在前面的教程中,我们已经通过 self.crawl 接口提交了 URL 进行了抓取。这些抓取就是通过 HTTP 协议传输的。
在抓取过程中,你可能会遇到类似 403 Forbidden,或者需要登录的情况,这时候你就需要正确的 HTTP 参数进行抓取了。
一个典型的 HTTP 请求包如下,这个请求是发往 http://example.com/ 的:
1 | GET / HTTP/1.1 |
- 请求的第一行包含
method,path和 HTTP 协议的版本信息- 余下的行被称为 header,是以
key: value的形式呈现的- 如果是 POST 请求,在请求结尾可能还会有
body内容
你可以通过前面用过的 Chrome Developer Tools 工具查看到这些信息:
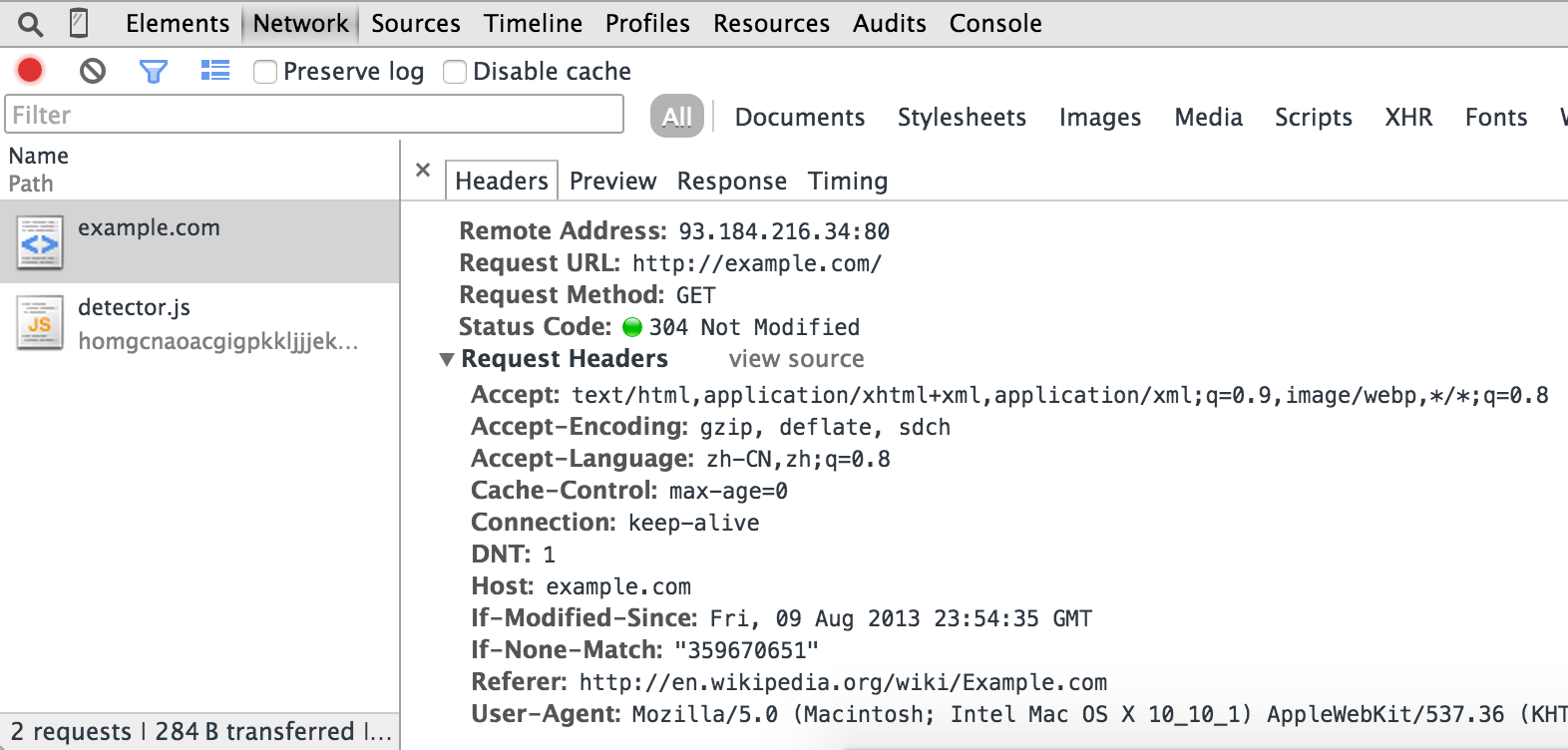
在大多数时候,使用正确的 method, path, headers 和 body 总是能抓取到你需要的信息的。
HTTP Method
HTTP Method 告诉服务器对 URL 资源期望进行的操作。例如在打开一个 URL 的时候使用的是 GET 方式,而在提交数据的时候一般使用 POST。
TODO: need example here
HTTP Headers
HTTP Headers 是请求所带的一个参数列表,你可以在 这里 找到完整的常用 Headers 列表。一些常用的需要注意的有:
User-Agent
UA 是标识你使用的浏览器,或抓取程序的一段字符串。pyspider 使用的默认 UA 是 pyspider/VERSION (+http://pyspider.org/)。网站常用这个字符串来区分用户的操作系统和浏览器,以及判断对方是否是爬虫。所以在抓取的时候,常常会对 UA 进行伪装。
在 pyspider 中,你可以通过 self.crawl(URL, headers={'User-Agent': 'pyspider'}),或者是 crawl_config = {'headers': {'User-Agent': 'xxxx'}} 来指定脚本级别的 UA。详细请查看 API 文档。
Referer
Referer 用于告诉服务器,你访问的上一个网页是什么。常常被用于防盗链,在抓取图片的时候可能会用到。
X-Requested-With
当使用 XHR 发送 AJAX 请求时会带上的 Header,常被用于判断是不是 AJAX 请求。例如在 北邮人论坛 中,你需要:
1 | def on_start(self): |
带有 headers={'X-Requested-With': 'XMLHttpRequest'} 才能抓取到内容。
HTTP Cookie
虽然 Cookie 只是 HTTP Header 中的一个,但是因为非常重要,但是拿出来说一下。Cookie 被 HTTP 请求用来区分、追踪用户的身份,当你在一个网站登录的时候,就是通过写入 Cookie 字段来记录登录状态的。
当遇到需要登录的网站,你需要通过设置 Cookie 参数,来请求需要登录的内容。Cookie 可以通过开发者工具的请求面板,或者是资源面板中获得。在 pyspider 中,你也可以使用 response.cookies 获得返回的 cookie,并使用 self.crawl(URL, cookie={'key': 'value'}) 来设置请求的 Cookie 参数。