如何抓取WEB页面
好忙好忙,忙到打完dota,看完新番,写完一个外挂就懒得更新blog的地步。。。一不小心从事spider已经快3年了,也没给爬虫写过点什么。本来打算趁着十一写个什么《三天学会爬虫》什么的,但是列了下清单,其实爬虫这东西简单到爆啊。看我一天就把它搞定了(・ω<)☆
##HTTP协议
WEB内容是通过HTTP协议传输的,实际上,任何的抓取行为都是在对浏览器的HTTP请求的模拟。那么,首先通过 http://zh.wikipedia.org/wiki/超文本传输协议 来对HTTP协议来进行初步的了解:
- HTTP通常通过创建到服务器80端口的TCP连接进行通信
- HTTP协议的内容包括请求方式(method), url,header,body,通常以纯文本方式发送
- HTTP返回内容包括状态码,header,body,通常以纯文本方式返回
- header以及body间以CRLF(\r\n)分割
由于富web应用越来越盛行,单纯的HTTP协议已经不能满足 -人类的欲望- 人们的需求了,websocket, spdy等越来越多的非HTTP协议信息传输手段被使用,但是目前看来,web的主要信息依旧承载于http协议。
HTTP请求
现在打开 chrome>菜单>工具>开发者工具 切换到network面板,访问 http://www.baidu.com/,点击红色高亮处的view source:
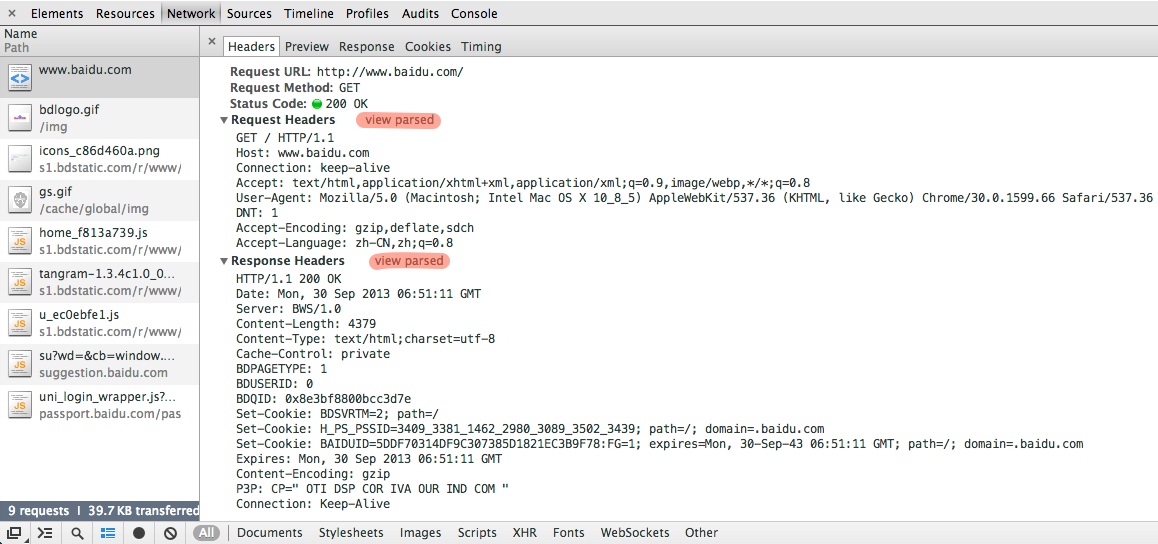
我们可以看到一个真实的HTTP请求的全部内容(这里的换行均为CRLF):
GET / HTTP/1.1 Host: www.baidu.com Connection: keep-alive Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8 User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/30.0.1599.66 Safari/537.36 DNT: 1 Accept-Encoding: gzip,deflate,sdch Accept-Language: zh-CN,zh;q=0.8
请求中的第一行称为Request-Line,包含了请求方式 URL HTTP版本,在上面的例子中,这个请求方式(method)为 GET,URL为 /, HTTP版本为 HTTP/1.1 。
注意到这里的URL并不是我们访问时的 http://www.baidu.com/ 而只是一个
/,而www.baidu.com的域名在HeaderHost: www.baidu.com中体现。这样表示请求的资源/是位于主机(host)www.baidu.com上的,而GET http://www.baidu.com/ HTTP/1.1则表示请求的资源位于别的地方,通常用于http代理请求中。
请求的后续行都是Header,其中比较重要的header有 Host, User-Agent, Cookie, Referer, X-Requested-With (这个请求中未展现)。如果是POST请求,还会有body。
虽然并不需要理解HTTP请求,只要参照chrome中展示的内容模拟请求就可以抓取到内容,但是学习一下各个header的作用有助于理解哪些元素是必须的,哪些可以被忽略或修改。
更多内容可以通过以下链接进行进一步学习:
http://zh.wikipedia.org/wiki/URL
http://en.wikipedia.org/wiki/Query_string
http://en.wikipedia.org/wiki/HTTP_POST
http://en.wikipedia.org/wiki/List_of_HTTP_header_fields
抱歉很多内容无法找到好的中文版本,欢迎在留言中提供
好了,这就是一个请求的全部,只要正确模拟了method,uri,header,body 这四要素,任何内容都能抓下来,而所有的四个要素,只要打开 chrome>菜单>工具>开发者工具 切换到network面板 就能看到,怎么样,很简单吧!
现在我们就可以通过curl命令来模拟一个请求:
curl -v -H "User-Agent: Chrome" http://www.baidu.com/
其中-v用于显示了请求的内容,-H指定header,具体curl的使用方式可以man curl或者你可以在chrome或者其他平台上找到很多类似的工具。
如果想看到请求是否正确,可以curl http://httpbin.org/get这个地址,它会返回经过解析的请求内容,来看看你的请求是否符合预期(http://httpbin.org/中有包括POST在内的完整API)
HTTP返回
下面展示了一个http返回的header部分,body内容被省略:
HTTP/1.1 200 OK Date: Mon, 30 Sep 2013 06:51:11 GMT Server: BWS/1.0 Content-Length: 4379 Content-Type: text/html;charset=utf-8 Cache-Control: private BDPAGETYPE: 1 BDUSERID: 0 BDQID: 0x8e3bf8800bcc3d7e Set-Cookie: BDSVRTM=2; path=/ Set-Cookie: H_PS_PSSID=3409_3381_1462_2980_3089_3502_3439; path=/; domain=.baidu.com Set-Cookie: BAIDUID=5DDF70314DF9C307385D1821EC3B9F78:FG=1; expires=Mon, 30-Sep-43 06:51:11 GMT; path=/; domain=.baidu.com Expires: Mon, 30 Sep 2013 06:51:11 GMT Content-Encoding: gzip P3P: CP=" OTI DSP COR IVA OUR IND COM " Connection: Keep-Alive
其中第一行为 HTTP版本 状态码 状态文字说明 之后的内容都是header,其中比较重要的有:Content-Type, Set-Cookie, Location, Content-Encoding(参见 HTTP_header#Requests)。返回之后的内容就是我们看到的网页内容了。
返回中最重要的是状态码和body中的内容,状态码决定抓取是否成功(200),是否会有跳转 (HTTP状态码),内容就是我们关心的内容了。
其他
http库
在实际抓取中,选择一个方便的HTTP库会帮你解决很多http的细节问题,比如http库会帮你:
- 建立http连接
- 设定常用header,生成正确的http请求
- get/post参数编码
- 跳转重定向
- 自动保存处理cookie
- 返回gzip解压,内容编码
python中推荐 requests,在命令行中我一般用curl进行调试。
AJAX
现在越来越多的页面使用了AJAX技术,表现为内容并不在打开的页面的源码中,而是通过称为 AJAX 的技术,在页面打开后加载的。但实际上,AJAX也是通过HTTP传送信息的,只不过内容来自于页面发起的另一个http请求,通过查看chome中的network列出的页面所有请求,一定可以找到内容,之后只需要模拟对应的这个请求即可。
HTML内容解析
web页面大都以HTML编写,对于简单的内容提取,使用正则即可。但是对付复杂的内容提取需求正则并不是一个好的选择(甚至称不上一个正确的选择),一款HTML/XML解析器+xpath/css selector是一个更有效的选择。
富web应用
对于富web应用,可能分析AJAX请求,和内容提取的代价太高。这时可能需要上最后手段——浏览器渲染。通过 phantomjs 或类似浏览器引擎,构建一个真实的浏览器执行js、渲染页面。